Regarding “Change datasource in a saved project”:
Could you please let me know if it is possible to change only the file to be loaded for a created project? Currently, it is possible to display the same analysis screen by applying the layout file, but it can be a bit cumbersome when there are many files to load or when there are many analysis screens.
It would be greatly convenient if this operation could be performed, especially in projects using data-sync. I would appreciate it if you could consider developing it.
Regarding “data preprocess workflow”:
I would like to hear your opinion on this matter. While it is generally based on loading data into datagrok after data preprocessing, sometimes we need to start the analysis from data that has not been preprocessed. In such cases, is there a way to register a function in datagrok in advance to split the values with inequality signs (e.g., >10) into “xxx_sign: >” and “xxx_value: 10” for columns where the activity value is entered (xxx being the original column name)?
It is probably a functionality provided by the current datagrok, but if possible, I would appreciate it if you could share a simple example.
Hi,
Could you please let me know if it is possible to change only the file to be loaded for a created project? Currently, it is possible to display the same analysis screen by applying the layout file, but it can be a bit cumbersome when there are many files to load or when there are many analysis screens.
It would be greatly convenient if this operation could be performed, especially in projects using data-sync. I would appreciate it if you could consider developing it.
Not sure I understand correctly.
Do you want to open the project, change one single file and save it?
I think it’s impossible, but let me better understand the use case.
1 Like
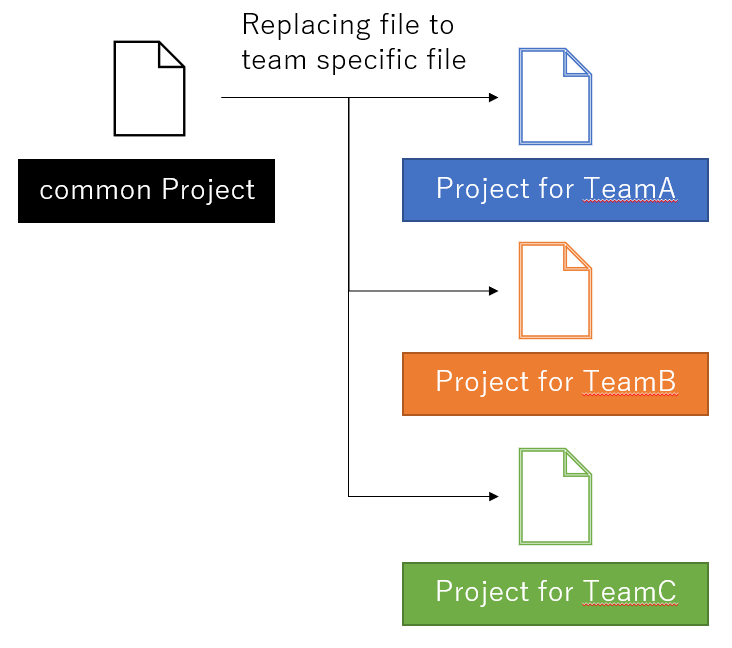
I am thinking I would like to make a common “Project” as template for multiple teams. Data tables for each team have many common columns and some team specific columns.
Although this idea might not align with datagrok’s philosophy, if I can replace file to load, I can re-use common Project and make team specific Project efficiently.
I would like to hear opinion for my question. I appreciate your consideration in advance.
So, you have multiple Data Sources for different teams, but you want to use same visualizations?
We have Data Sync feature now, but unfortunately it does not support parameters, only fixed script.
I’m thinking of a system that asks something to user before project loads and loads project accordingly to users input, passing it to Data Sync data source function.
Does it make sense to you?
I’m thinking of a system that asks something to user before project loads and loads project accordingly to users input, passing it to Data Sync data source function.
Dear Alex,
Thanks for your comment and that’s exactly what I wanted. I am confident that it is definitely useful because one Project can be utilized in multiple scenarios.
To be easier to imagine, I set exemplified data source files are something like below (column names are listed):
File for team A: activity_A1, activity_A2, common1, common2, common3
File for team B: activity_B1, activity_B2, activity_B3, common1, common2, common3
File for team C: activity_C1, activity_C2, activity_A1, common1, common2, common3
For clarification, team C is focusing on selectivity between activity_A1 and activity_C1 so activity_A1 is included in the file for team C.
Additionally, I imagine I will load multiple files for each Project. That’s why selecting files to be loaded before opening Project will be nice feature.
1 Like
What about file names? Who determines, which files to use?
Do teams make decisions, or it should be pre-set-up by admin?
For instance, how user decides if he needs activity_A1 or activity_B1?
I have to ask questions to better understand your problem and propose a better solution.
Dear Alex,
Thank you for your questions. I should clarify more to organize my idea.
File names and common column names are fixed by Admin. Let’s say, we start loading main.sdf and suppl.csv .
In main.sdf, some columns are independent and some are common. The number of columns and their names related to activity against therapeutic target vary depending on each team. Common columns also exists and their name are fixed by Admin.
File for team A: Cmpd_ID, activity_A1 , activity_A2, common1, common2, common3
File for team B: Cmpd_ID, activity_B1, activity_B2, activity_B3, common1, common2, common3
File for team C: Cmpd_ID, activity_C1, activity_C2, activity_A1 , common1, common2, common3
In suppl.csv , their column names are completely common like below and their name are fixed by Admin. Additionally, they are linked with corresponding main.sdf by Cmpd_ID.
File for team A: Cmpd_ID, common4, common5, common6
File for team B: Cmpd_ID, common4, common5, common6
File for team C: Cmpd_ID, common4, common5, common6
So, the bottomline is:
You have N different files for teams, and they contain similar data. You want similar visualizations for files.
Last (I think) questions,
is the choice of the file is a free will of a team? Shoud the access be restricted?
Files are one-to-one with teams, or many-to-many?
Who decides which files team has access to?
Thanks!
You have N different files for teams, and they contain similar data. You want similar visualizations for files.
Exactly!
is the choice of the file is a free will of a team? Shoud the access be restricted?
Who decides which files team has access to?
Only administrators can choose files to prepare each team’s visualization, but end-users can access files freely (no access limit). Hence, end-users can load files when opening Project.
Files are one-to-one with teams, or many-to-many?
In my mind, I am planning to prepare separated folder for each team like beow. Similar files are stored for each team. Files names will be almost the same (team’s name + common name) or I can completely align file names if you want.
Once similar visualizations are created, all teams can start from the same starting point for their analysis and each team will evolve their visualizations with progress of their task like team C.
team A folder
team B folder
team C folder
C_main.sdfC_suppl.csvC_addional_data.csv ( ← added later after team wants to add additional visualization)
I am happy to share my ideas and discuss. If you have any questions, please let me know.
I think I will come up with POC of a system like this in a while.
I see it like a project with data sync enbled, that linked to a function that asks user which folder he want to access each time he opens the project.
1 Like
Hi, please take a look. It’s a quick and dirty prototype of how it can look.
If you run two functions from DG console:
YourPackage:provideMainDataSource()
YourPackage:provideSubDataSource()
you’ll get two tables, and then, if you save them so a project with Data Sync enabled for both of them, the project will show a dialog.
Is it something like you described?
Please note, it is an early prototype, just to illustrate the idea.
The code below, just for reference:
let mainTable: Promise<DG.DataFrame>;
let supTable: Promise<DG.DataFrame>;
let dialog: DG.Dialog | undefined;
//name: provideMainDataSource
//output: dataframe table
export async function provideMainSource(): Promise<DG.DataFrame> {
if (dialog == undefined)
showDialog();
return await mainTable;
}
//name: provideMainDataSource
//output: dataframe table
export async function provideSupSource(): Promise<DG.DataFrame> {
if (dialog == undefined)
showDialog();
return await supTable;
}
async function showDialog(): Promise<void> {
dialog = ui.dialog('Choose data');
const input = ui.input.choice<number>('Rows Count', {items: [10, 100, 1000]});
dialog.add(input);
const dialogOk = new Promise<void>((resolve, reject) => {
dialog!.onOK(resolve);
dialog!.onCancel(() => reject('No data selected'));
});
function getData(getDf: () => Promise<DG.DataFrame>): Promise<DG.DataFrame> {
return new Promise<DG.DataFrame>(async (resolve, reject) => {
try {
await dialogOk;
resolve(await getDf());
} catch (x) {
reject(x);
}
});
}
mainTable = getData(async () => grok.data.demo.demog(input.value));
supTable = getData(async () => grok.data.demo.geo(input.value));
dialog.show();
try {
await dialogOk;
//open additional projects;
} catch (_) {
} finally {
dialog = undefined;
}
}
Hi, Alex,
Thank you for your effort and I apologize for the delayed response.
I believe this prototype, which allows input of parameters when loading a project, is getting closer to what we want to achieve.
In this prototype, we are passing the value of a variable, but if we can specify the location of the file to be loaded, it seems that we can achieve “Create similar Projects from similar files”. Besides, current one accepts input on refreshing Project, but I am excited about the possibility of adding options to accept or not accept input, which would add additional option to users to reuse Projects other than “clone”.
Here, I have a question. If we are able to specify a file, do you envision that we would be able to specify a file in the same directory or also in different directory? The latter option would provide more flexibility, so it would be preferable.
Thank you again for come up with a soluton to deal with my request.
Best regards,
Kosuke
Dear Kosuke,
Thank you for your kind attention.
The problem requires the creation of code that can read a file through an API.
A corresponding GitHub issue has been created for this purpose: GitHub issue 2818.
We will keep you updated on the progress.
Best,
Olesia
1 Like
Let’s try to view it from another angle.
What if we set up a template project with all visualizations built on abstract (any team) data, and then use these visualizations as a template?
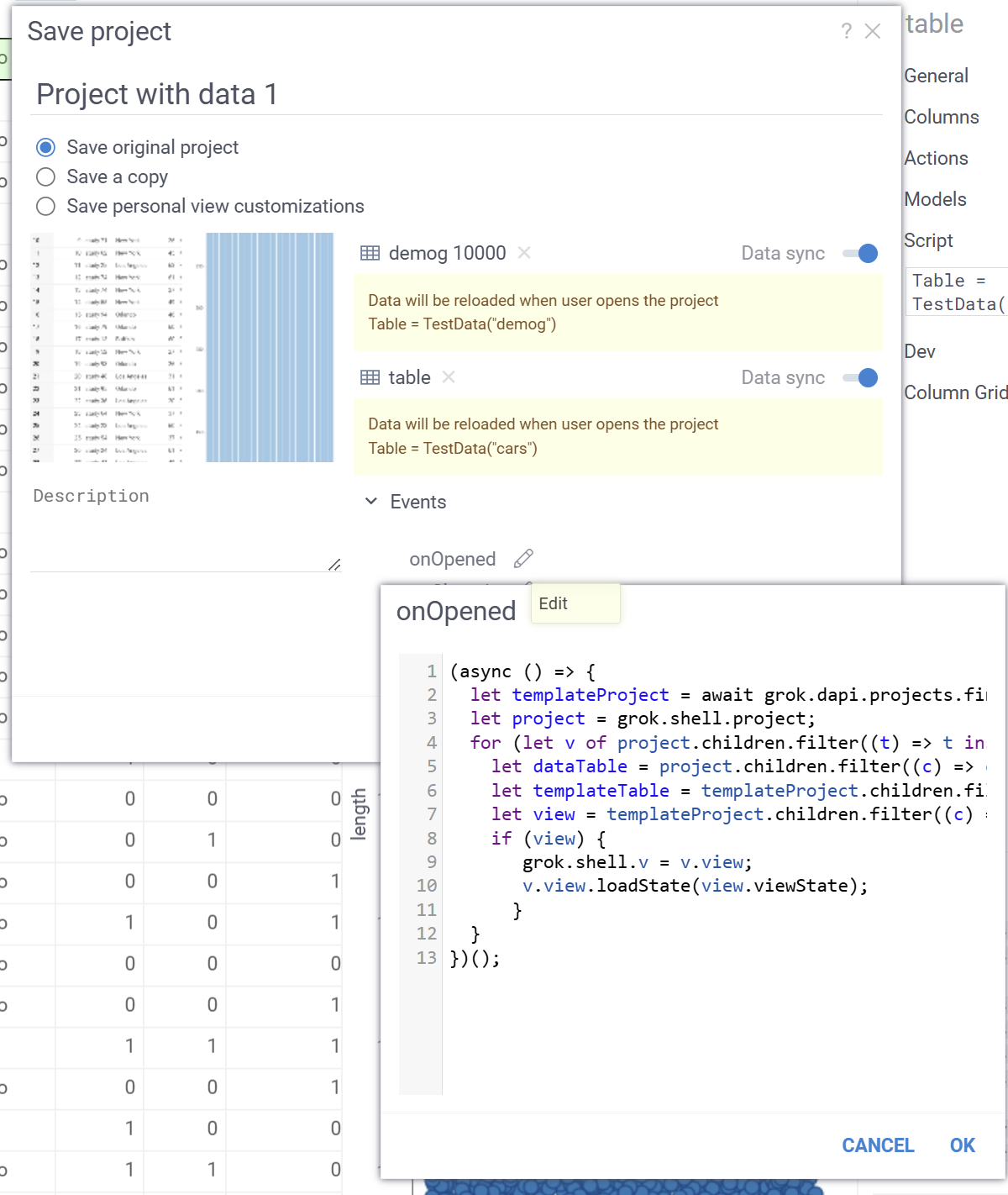
I’ve made a project with to tables with data sync enabled (just not to waste storage, as all I really need are views), set up a couple of viewers and saved it.
It has name Admin:TemplateProject.
Now, I open similar data and save a new project, enabling Data Sync, and pasting a little script to onOpened handler, that finds TemplateProject and gets all visualizations using table names match.
I’ve checked it on our dev, and it really works  Please let me know if it solves your task.
Please let me know if it solves your task.
Here is the script:
(async () => {
let templateProject = await grok.dapi.projects.find((await grok.functions.eval('Admin:TemplateProject')).id);
let project = grok.shell.project;
for (let v of project.children.filter((t) => t instanceof DG.ViewInfo)) {
let dataTable = project.children.filter((c) => c instanceof DG.TableInfo && c.id == v.table.id)[0];
let templateTable = templateProject.children.filter((c) => c instanceof DG.TableInfo && c.name == dataTable.name)[0];
let view = templateProject.children.filter((c) => c instanceof DG.ViewInfo && c.table?.id == templateTable?.id)[0]
if (view) {
grok.shell.v = v.view;
v.view.loadState(view.viewState);
}
}
})();
Unfortunately, it will work only on 1.19.0 or higher, but we release it soon.
Please, let me know, if you would like to arrange a meeting to discuss the problem or solution, and I will gladly help you to set it all up after 1.19.0 release.
1 Like
Hi Alex,
thank you for your effort and sorry for late reply due to long holidays.
New approach is also nice because it is easier to apply multiple views (or .layout) from Admin:TemplateProject. Let me have internal discussion and let you know later. Thank you for your kind note for additional meeting in case we need to clarify.
1 Like