Community
Cheminformatics updates
Announcements
chem
skalkin
April 6, 2021, 12:59am
8
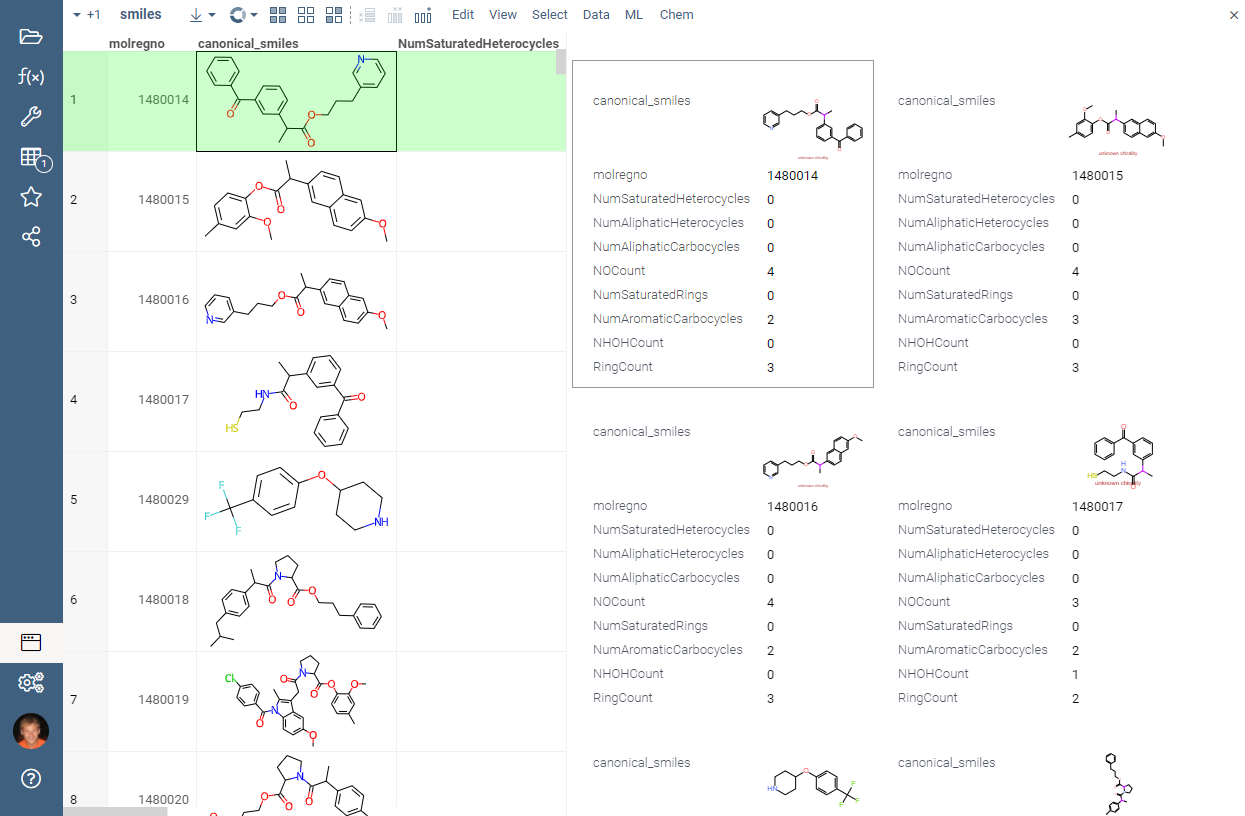
RDKit-based structure depiction is now completely integrated with the platform:
grid
tooltip
form
tile viewer
other viewers (bar chart, trellis plot, etc)
image
1245×816 108 KB
2 Likes
Platform Releases
show post in topic