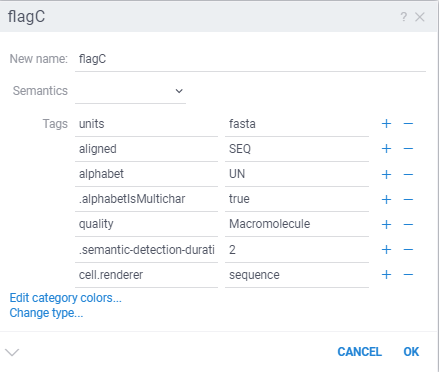
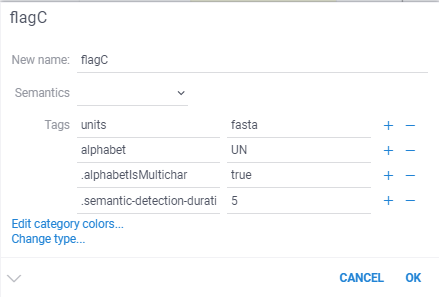
A certain string is being recognized as a sequence, so I changed it in the column properties to undo this. However, after saving and reopening the project, it reverts back.
↓
Due to this, the legend of scatter plot’s color does not work, and making it difficult to analyze each chemotype.
How can I fix the issue?
Any comments or suggestions will be greatly appreciated.
Thanks,
Hello!
I am able to reproduce the false detection of Macromolecule on this data and return soon with a fix for it.
To prevent the column semantic type from being redetected while opening the project, try setting the quality tag to a string instead of just deleting it.
Dear Datagrok team,
I would like to know how to solve the same issue again.
If possible, I want to avoid setting data type again when opening saved project. It seems current version consider datatype and define suitable data type on opening projects.
Are there any good detours not to be recognized text as peptide sequence? Any comments and suggestions are well appreciated.
Best regards,
Kosuke
Hi Kosuke.
Currently, Data-sync projects do not store data, and re-initialize it when project is opened.
As you know, some names (especially IUPAC) can be very similar to dash separated sequences. I will try to improve the macro-molecule detectors for false positives. If you can provide some examples of names which are recognized as sequences, that might help a lot.
We can also consider adding a small script to project that will set the correct tags. Let me know if this option is suitable for you, then I can assist you with it.
Best.
Davit.
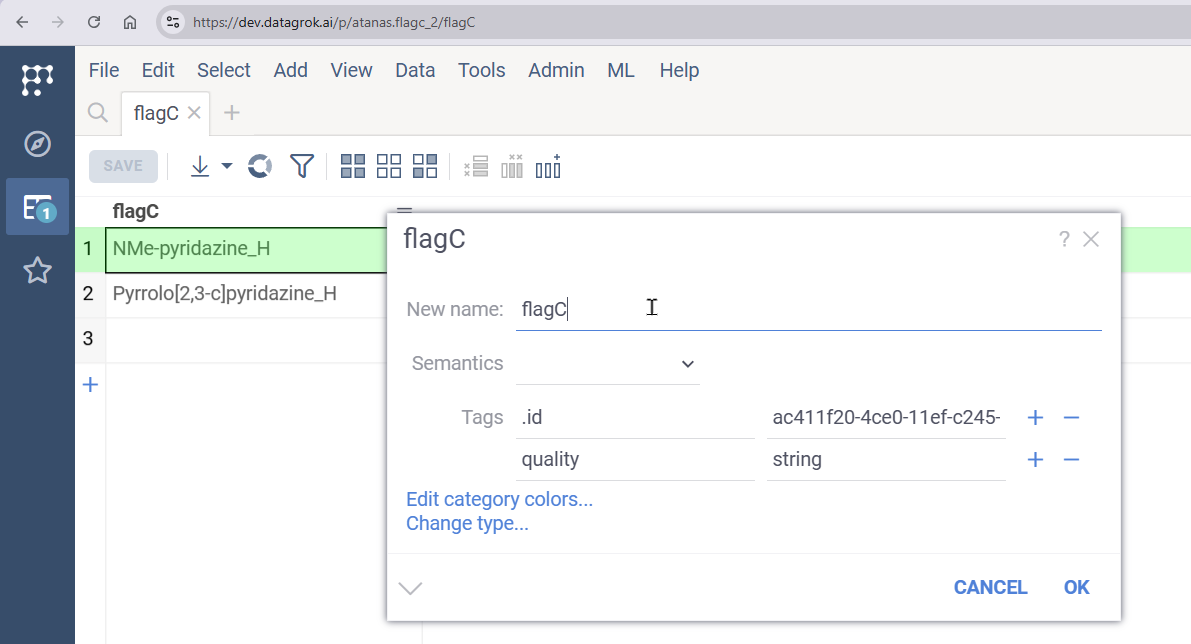
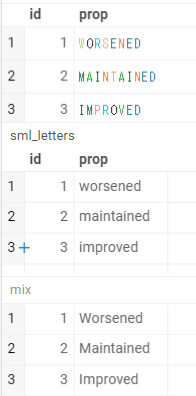
In my case, an incorrectly recognized column only contains ‘MAINTAINED’, ‘IMPROVED’ and ‘WORSENED’ and is shown like below.
Perhaps, the easiest way to solve is to change from capital to small letters or change contents into shorter names (I am sorry but I haven’t tried neither ways). Although I can modify ‘MAINTAINED’, ‘IMPROVED’ and ‘WORSENED’ into suitable words, it would be appreciated if you could assist my issue.
Dear Davit,
I carried out simple experiment.
In my case, my issue was solved by just changing from all-capital-word to all-small-letters or head-capital word.
Since I am planning to modify my data for the issue for further analysis, you don’t need worry about MY issue.
On the other hand, similar requests would occur again. So, it would definitely helpful if you could consider how to dare to set datatype as string when opening projects.
Best,
Kosuke
Hi Kosuke!
Thanks for the effort!
I went through the Bio detector and made one improvement that will also fix the wrong detection from the example. The change will be available in Bio package version 2.17.6, which you can install after the update (As mentioned, due to change in the API of NPM, newest packages are not loaded correctly in current version).
Best.
Davit.